|
|
PacemakerEtCorosyncIntroduction en s'occupant de leur dÚmarrage, redÚmarrage, arrŕt. La communication entre vos noeuds et la gestion du cluster en lui-mŕme seront assurÚes par une brique dÚdiÚe comme par exemple Corosync. Son r˘le est de se charger du heartbeat (battement de cťur de notre cluster) et d'avertir Pacemaker du changement dĺÚtat des nťuds. Il faut Úgalement garder en tŕte que le fait d'avoir un cluster pour le service DHCP n'exclut pas d'avoir des problŔmes. Un cluster peut se trouver confrontÚ Ó un problŔme de taille : le split-brain. C'est le principal problŔme Ó Úviter. Le split-brain peut intervenir quand chaque nťud de votre cluster croit son voisin hors service. Il va alors prendre la main : chaque nťud est donc maţtre et fournit le service. Les effets de bords peuvent ŕtre gŕnants dŔs lors quĺon utilise une ressource partagÚe. Installation : # apt-get install corosync # apt-get install pacemaker # apt-get install crmsh Crmsh est un CLI permettant de configurer votre Cluster. Avant d'effectuer la configuration, ouvrir les ports nÚcessaires Ó Corosync et autoriser le multicast : # iptables -A INPUT -p udp --dport 5404 -j ACCEPT # iptables -A INPUT -p udp --dport 5405 -j ACCEPT # iptables -A INPUT -m pkttype --pkt-type multicast -j ACCEPT # iptables-save > /etc/iptables_rules.save Configuration de Corosync : Remarque : Ce fichier doit ŕtre le mŕme sur l'ensemble de vos nťuds. Lorsque la configuration du fichier sera terminÚ, une copie sera nÚcessaire sur l'autre nťud. # vi /etc/corosync/corosync.conf totem { version: 2 threads: 0 cluster_name: ntp_route token: 5000 token_retransmits_before_loss_const: 20 join: 1000 consensus: 7500 max_messages: 20 secauth: on # On utilise une clÚ pour autoriser un nťud Ó se connecter au cluster. interface { ringnumber: 0 bindnetaddr: 192.168.1.0 mcastaddr: 226.94.1.1 mcastport: 5405 ttl: 1 } } logging { to_logfile: yes logfile: /var/log/corosync/corosync.log to_syslog: yes debug: off timestamp: on logger_subsys { subsys: QUORUM debug: off } } quorum { provider: corosync_votequorum expected_votes: 2 } Pour Úviter le split-brain, il faut dÚclarer une deuxiŔme interface. Exemple : rrp_mode: active
interface {
ringnumber: 0
bindnetaddr: 194.214.124.0
mcastaddr: 226.94.1.1
mcastport: 5405
}
interface {
ringnumber: 1
bindnetaddr: 192.168.1.0
mcastaddr: 226.94.2.1
mcastport: 5405
}
Remarque : [TOTEM ] Marking seqid 3608 ringid 1 interface 192.168.0.2 FAULTY administrative intervention required. La commande suivante, permet de donner l'Útat de vos interfaces : 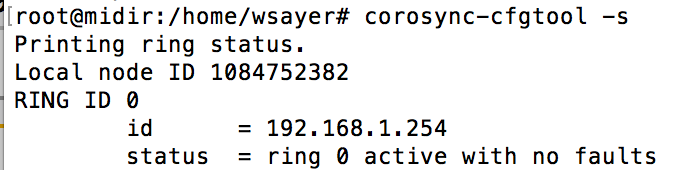 IntÚgration de Pacemaker et activation de corosync : # mkdir /etc/corosync/service.d/ Nous allons maintenant ajouter le service Pacemaker dans notre cluster Corosync.  DÚmarrez le service corosync # systemctl start corosync Authentification : Lors de l'installation de Corosync, une clÚ a ÚtÚ gÚnÚrÚ pour permettre l'authentification de vos noeuds. Nous allons Úcraser cette clÚ et en construisant sur le noeud PRIMAIRE la clÚ Ó partager entre les noeuds du cluster (en utilisant le paquet haveged). Le servcie PACEMAKER
Dans les logs, tail -f /var/log/corosync/corosync.conf, vous pourrez voire le bon fonctionnement du cluster, Úgalement lors d'une vÚrification du status de Corosync, systemctl status corosync La commande ps va nous permettre de retrouver ces processus, ici avec "version" Ó 1 dans le fichier /etc/corosync/corosync.conf : # ps -e f 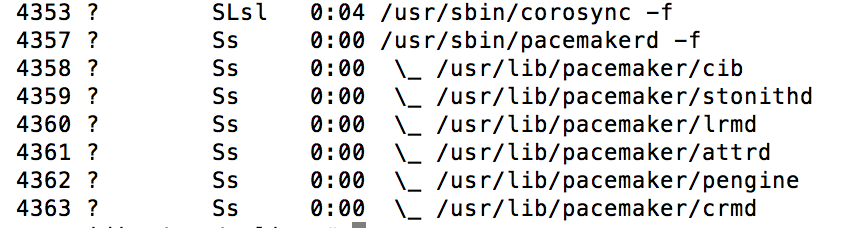 Surveiller l'Útat du Cluster : La commande crm_mon est un moniteur en temps rÚel pour afficher lĺÚtat du cluster. Avec cette outil vous allez retrouver la liste des nťuds, leur Útat, le nom du coordinateur dÚsignÚ (DC), le hearbeat utilisÚ, etc. # crm_mon -1 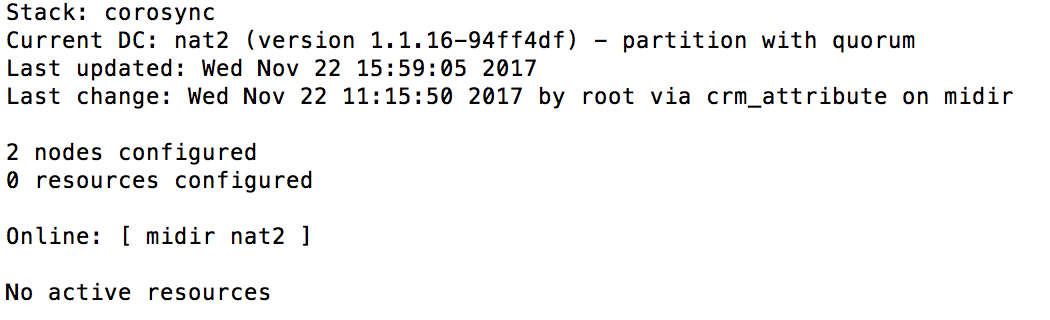 Voir la configuration initiale de PACEMAKER : # crm config show 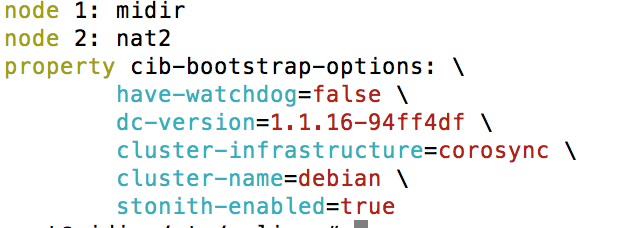 # crm config show xml 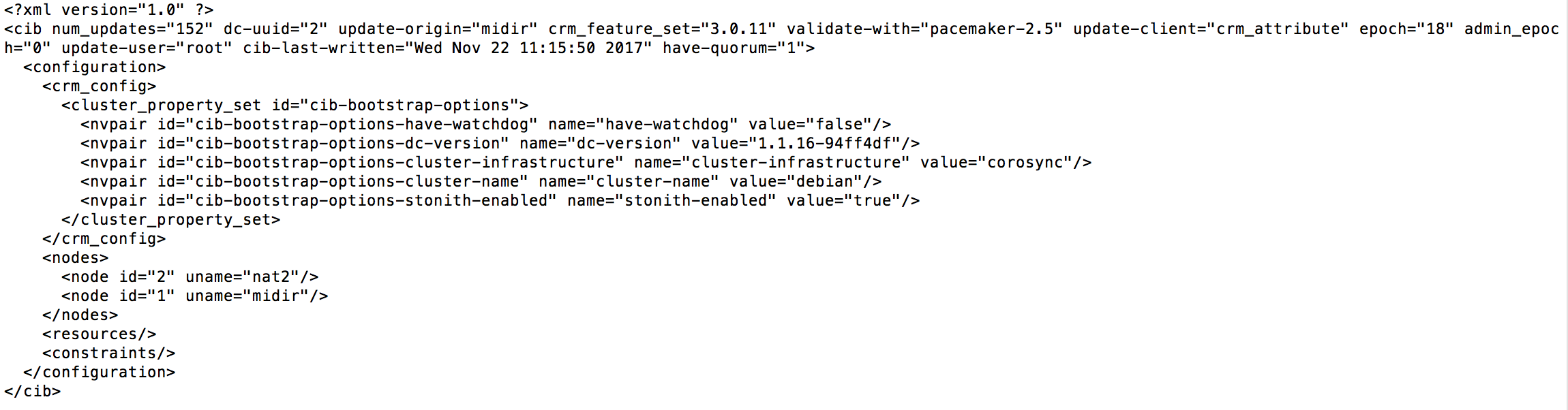 ATTENTION ! Veillez Ó ne JAMAIS modifier le fichier de configuration /var/lib/heartbeat/crm/cib.xml Ó la main. Cĺest une rŔgle de base. ParamÚtrage du Cluster : Attribution d'une adresse IP virtuelle au cluster. Nous utiliserons la cli CRM (Cluster Resource Manager) pour crÚer notre configuration du cluster. # crm crm(live)# cib new ma-config-cluster INFO: cib.new: ma-config-cluster shadow CIB created On dÚsactive STONITH. Dans notre cas, STONITH est une fonction de sÚcuritÚ des donnÚes lors du basculement entre les deux serveurs d'un cluster. Il est garant de lĺintÚgritÚ des donnÚes Ó chaque bascule. Ici nous nĺen avons pas besoin pour un cluster de serveur NAT/DHCP. crm(ma-config-cluster)# configure crm(ma-config-cluster)configure# property stonith-enabled=false Et enfin on assigne une adresse IP virtuelle au cluster et on gŔre la bascule entre les noeuds : crm(ma-config-cluster)configure# primitive failover-ip ocf:heartbeat:IPaddr params ip=192.168.1.2 op monitor interval=10s Descriptions des arguments :
On vÚrifie et valide les commandes : crm(ma-config-cluster)configure# verify crm(ma-config-cluster)configure# end There are changes pending. Do you want to commit them? y crm(ma-config-cluster)# crm(ma-config-cluster)# cib use live crm(live)# cib commit ma-config-cluster INFO: commited 'ma-config-cluster' shadow CIB to the cluster crm(live)# quit bye Le cluster est maintenant activÚ et fonctionnel ! # crm_mon --one-shot -V # crm_mon -1  Nettoyage du message Actions ayant ÚchouÚ dans la configuration du cluster Pacemaker / Corosync. # crm_mon -1 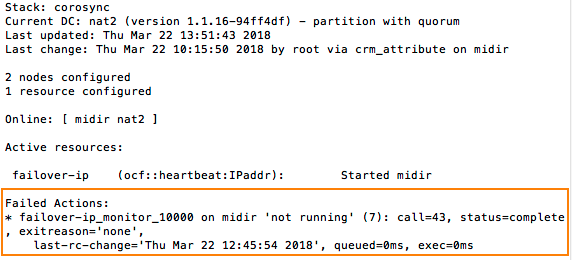 Pour supprimer les erreurs, exÚcutez la commande suivante : # crm_resource -P Sur le serveur secondaire : S'assurer que la clÚ authkey a bien ÚtÚ copiÚ sur le serveur secondaire avec comme utilisateur et groupe root et avec les droits 400. # ls -l /etc/corosync  RedÚmarrez les services pacemaker et corosync : # systemctl restart pacemaker # systemctl restart corosync # update-rc.d pacemaker defaults # crm_mon -1 Tester le basculement de lĺIP sur le second noeud : Positionnez le noeud midir en standbye : # crm node standby midir 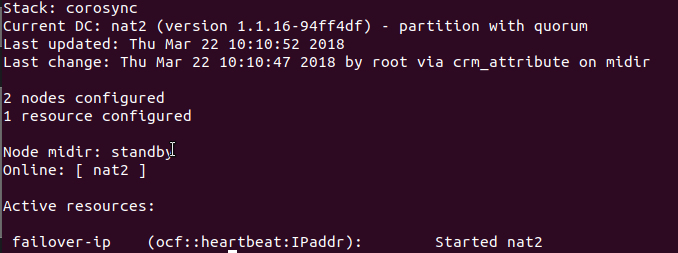 Autres documentations :
Cĺest une commande incontournable pour rÚcupÚrer Ó nĺimporte quel moment lĺÚtat du cluster. Il peut gÚnÚrer du html, propose une interface cgi, peut dialoguer avec dĺautres outils de monitoring (centreon, nagiosů). Le paramŔtre -1 permet dĺobtenir une seule sortie : STONITH |